kafka基础整理
定义:它同时也是一款开源的基于发布订阅模式的消息引擎系统。
基本概念

消息:Kafka 中的数据单元被称为<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">消息</font>,也被称为记录,可以把它看作数据库表中某一行的记录。
批次:为了提高效率, 消息会<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">分批次</font>写入 Kafka,批次就代指的是一组消息。
主题:消息的种类称为 <font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">主题</font>(Topic),可以说一个主题代表了一类消息。相当于是对消息进行分类。主题就像是数据库中的表。
分区:主题可以被分为若干个分区(partition),同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">伸缩性</font>,单一主题中的分区有序,但是无法保证主题中所有的分区有序

生产者:向主题发布消息的客户端应用程序称为<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">生产者</font>(Producer),生产者用于持续不断的向某个主题发送消息。
消费者:订阅主题消息的客户端程序称为<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">消费者</font>(Consumer),消费者用于处理生产者产生的消息。
消费者群组:生产者与消费者的关系就如同餐厅中的厨师和顾客之间的关系一样,一个厨师对应多个顾客,也就是一个生产者对应多个消费者,<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">消费者群组</font>(Consumer Group)指的就是由一个或多个消费者组成的群体。
偏移量:**<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">偏移量</font>**(Consumer Offset)是一种元数据,它是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
broker: 一个独立的 Kafka 服务器就被称为 <font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">broker</font>,broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。
broker 集群:broker 是<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">集群</font> 的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">集群控制器</font>的角色(自动从集群的活跃成员中选举出来)。
副本:Kafka 中消息的备份又叫做 <font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">副本</font>(Replica),副本的数量是可以配置的,Kafka 定义了两类副本:领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
主题(topic),分区(Partition),分段,副本
一个主题下面有多个分区,每个分区的内容又不相同
分区写入策略
所谓分区写入策略,即是生产者将数据写入到kafka主题后,kafka如何将数据分配到不同分区中的策略。
常见的有三种策略,轮询策略,随机策略,和按键保存策略。其中轮询策略是默认的分区策略,而随机策略则是较老版本的分区策略,不过由于其分配的均衡性不如轮询策略,故而后来改成了轮询策略为默认策略。
分区之后还能产生副本
kafaka为什么要分区
负载均衡和水平拓展,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力。
为了性能考虑,如果topic内的消息只存于一个broker,那这个broker会成为瓶颈,无法做到水平扩展。
2.如果没有分区,topic中的segment消息写满后,直接给订阅者不是也可以吗 ?
“segment消息写满后”,consume消费数据并不需要等到segment写满,只要有一条数据被commit,就可以立马被消费
segment对应一个文件(实现上对应2个文件,一个数据文件,一个索引文件),一个partition对应一个文件夹,一个partition里理论上可以包含任意多个segment。
消息传递
生产者
- 首先被封装成一个producerRecord对象
- 进行序列化
- 进行分区处理(决定在哪个分区
- 分区好的信息不会直接放进服务端,而是放入生产者的缓存区,多条消息被封装成一个batch,默认是16K
- sender线程启动后从缓存中获取可以发送的批次
- 发送!
创建一个ProducerRecord 首先序列化,如果没有指定分区,那么就是用key的hash作为分区,如果再没有,就循环 分配一个
ack机制
Kafka的Producer有三种ack机制,参数值有0、1 和 -1
- 0: 相当于异步操作,Producer 不需要Leader给予回复,发送完就认为成功,继续发送下一条(批)Message。此机制具有最低延迟,但是持久性可靠性也最差,当服务器发生故障时,很可能发生数据丢失。
- 1: Kafka 默认的设置。表示 Producer 要 Leader 确认已成功接收数据才发送下一条(批)Message。不过 Leader 宕机,Follower 尚未复制的情况下,数据就会丢失。此机制提供了较好的持久性和较低的延迟性。
- -1: Leader 接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都确认消息已同步,Producer 才发送下一条(批)Message。此机制持久性可靠性最好,但延时性最差。
消息压缩
compression.type
此参数来表示生产者启用何种压缩算法,默认情况下,消息发送时不会被压缩。该参数可以设置为 snappy、gzip 和 lz4,它指定了消息发送给 broker 之前使用哪一种压缩算法进行压缩。下面是各压缩算法的对比

一些配置:
batch.size
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次被填满,批次里的所有消息会被发送出去。不过生产者井不一定都会等到批次被填满才发送,任意条数的消息都可能被发送。
消费者

向群组中增加消费者水横向伸缩消费能力的主要方式。总而言之,我们可以通过增加消费者组的消费者来进行
水平拓展提升消费能力。这也是为什么建议创建主题时使用比较多的分区数。另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
消费者组和重平衡
消费者组
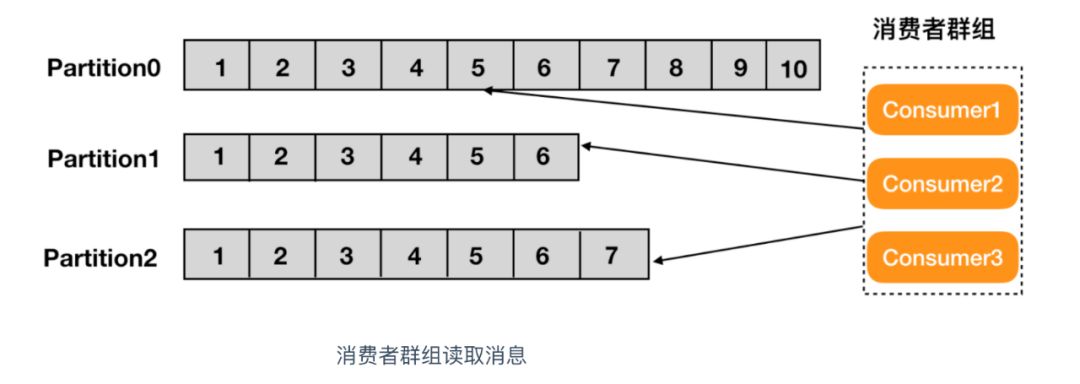
<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">消费者组(Consumer Group)</font>是由一个或多个消费者实例(Consumer Instance)组成的群组,具有可扩展性和可容错性的一种机制。消费者组内的消费者<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">共享</font>一个消费者组ID,这个ID 也叫做 <font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Group ID</font>,组内的消费者共同对一个主题进行订阅和消费,同一个组中的消费者只能消费一个分区的消息,多余的消费者会闲置,派不上用场。
我们在上面提到了两种消费方式
- 一个消费者群组消费一个主题中的消息,这种消费模式又称为
<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">点对点</font>的消费方式,点对点的消费方式又被称为消息队列 - 一个主题中的消息被多个消费者群组共同消费,这种消费模式又称为
<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">发布-订阅</font>模式
消费者重平衡
我们从上面的
<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">消费者演变图</font>中可以知道这么一个过程:最初是一个消费者订阅一个主题并消费其全部分区的消息,后来有一个消费者加入群组,随后又有更多的消费者加入群组,而新加入的消费者实例<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">分摊</font>了最初消费者的部分消息,这种把分区的所有权通过一个消费者转到其他消费者的行为称为<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">重平衡</font>,英文名也叫做<font style="color:rgb(10, 191, 91);background-color:rgb(243, 245, 249);">Rebalance</font>。
重平衡给消费者带来了高可用性和伸缩性。
消费者通过向组织协调者发送心跳来维护自己是消费者的一员并确认其拥有的分区。
如果过一段时间kafka停止发送心跳了,会话就会过期,那么组织协调者就会认为这个consumer已经死亡,就会触发一次重平衡。如果消费者宕机并且停止发送消息,组织协调者会等待几秒钟,确认它死亡了才会触发重平衡。在这段时间内,死亡的消费者将不处理任何消息。在清理消费者时,消费者将通知协调者它要离开群组,组织协调者会触发一次重平衡,尽量降低处理停顿。
消息分类
- 最多传递一次
- 最少传递一个
- 仅有一次传递
| 类型 | 消息是否会重复 | 消息是否会丢失 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|---|
| 最多一次 | 否 | 是 | 生产端发送消息后不用等待和处理服务端响应,消息发送速度会很快。 | 网络或服务端有问题会造成消息的丢失。 | 消息系统吞吐量大且对消息的丢失不敏感。例如:日志收集、用户行为等场景。 |
| 最少一次 | 是 | 否 | 生产端发送消息后需要等待和处理服务端响应,如果失败会重试。 | 吞吐量较低,有重复发送的消息。 | 消息系统吞吐量一般,但是绝不能丢消息,对于重复消息不敏感。 |
| 有且仅有一次 | 否 | 否 | 消息不重复,消息不丢失,消息可靠性很好。 | 吞吐量较低 | 对消息的可靠性要求很高,同时可以容忍较小的吞吐量。 |
进阶
kafka为什么这么快?
- 顺序读写
- 零拷贝
- 消息压缩
- 分批发送