分库分表
美团用的是取模分
基本概念
只分表:单表数据量大,读写出现瓶颈,这个表还能支撑未来几年的增长。
只分库:整个数据库出现性能瓶颈,例如数据库连接被打满了,或者并发量太大了,需要把库拆开
分库分表:单表数据量大,所在库也出现性能瓶颈,就要既分库又分表。
垂直拆分:把字段拆开到另一个表
水平拆分:把记录分开
分库分表的场景
一般情况下,单表数据量达到千万级别,就可以考虑分库分表了。
具体是否分库分表还需要看具体的业务场景,例如流水表,记录表数据量非常容易到达千万级、亿万级,需要在设计数据库表的阶段就进行分表,还有一些表虽然数据量只有几百万,但字段非常多,而且有很多text、blog格式的字段,查询性能也会很慢,可以考虑分库分表。
分库分表具体步骤
原则:
1 能不分就分表,优先进行数据库调优
2.分片数量尽量少。
分片尽量均匀分布在多个 DataHost 上,因为一个查询 SQL 跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量。
3.不要一个事务里跨越多个分片查询
尽量不要在一个事务中的 SQL 跨越多个分片,分布式事务一直是个不好处理的问题
拆分
- 业务拆分
- 混合业务拆分
- 具体业务拆分
- 电商网站:一个典型的混合业务,包含用户信息、订单信息、商品信息等。可以将用户信息、订单信息和商品信息分别拆分到不同的库或表中,以减少数据冗余并提高访问效率。
- 社交媒体平台:包含用户信息、好友关系、动态信息等。可以将用户信息和好友关系分离存储,以便更好地支持好友关系的查询和更新。
- 冷热分离
海量数据存储
分区
表分区是一种数据存储方案,可以解决单表数据较多的问题。
底层就是一张表的数据被拆到了多个表文件存储了;从逻辑看,他们对外是一张表。
所以想要提高磁盘IO,就得把这个放在多个磁盘中
分区策略:
- Hash
- 进行hash运算
- Range
- 分配几个区间,数值在这个区间的就存,0-10,11-20,大于20 等
- List
- 提前定好每个key可以放置的区间,不匹配的不能放进去
- Key
分表
垂直分表:字段分离(一些不常用的在另外一个表)
实际应用-sharding-jdbc
分片算法:
- 精确分片算法: = 和in
- 范围分片算法:between
- 复合分片算法:多个字段的值
- Hint分片算法:强制路由,
广播表:每个库中都一样,只要修改一个,别的也会进行同步(例如字典表)
绑定表:主表和子表,防止笛卡尔积(需要保证两个的分片策略相同)
通常在我们的业务中都会使用 <font style="color:rgb(25, 27, 31);background-color:rgb(248, 248, 250);">t_order</font> 和 <font style="color:rgb(25, 27, 31);background-color:rgb(248, 248, 250);">t_order_item</font> 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条<font style="color:rgb(25, 27, 31);background-color:rgb(248, 248, 250);">SQL</font>。
1 | |
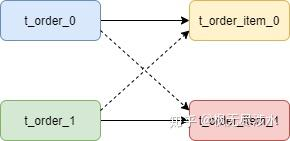
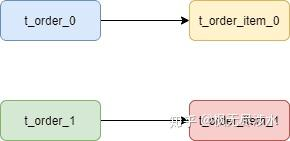
而配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 <font style="color:rgb(25, 27, 31);background-color:rgb(248, 248, 250);">t_order_0</font>和 <font style="color:rgb(25, 27, 31);background-color:rgb(248, 248, 250);">t_order_item_0</font> 表关联即可。
1 | |
分片策略:是分片算法+分片键
跨数据源的复杂查询
海量数据高并发的 OLTP 场景
由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降。通过 ShardingSphere 数据分片,按照某个业务维度,将存放在单一数据库中的数据分散地存放至多个数据库或表中,可以达到提升性能的效果。通过使用 ShardingSphere-JDBC 接入端,可以满足高并发的 OLTP 场景下的性能要求。
海量数据实时分析 OLAP 场景
在传统的数据库架构中,如果用户想要进行数据分析,需要先使用 ETL 工具,将数据同步至数据平台中,然后再进行数据分析,使用 ETL 工具会导致数据分析的实效性大打折扣。ShardingSphere-Proxy 提供静态入口以及异构语言的支持,独立于应用程序部署,适用于实时分析的 OLAP 场景。
分库分表常见问题参考答案(收录25年至今的牛客面经)
分库分表的常用中间件有哪些?
mycat sharding-jdbc
有哪些问题中间件无法提供帮助、只能改写业务代码的场景?
- 跨分片的复杂查询
使用了什么中间件?
mycat sharing
分库分表的实现场景和方式有哪些?
分表之后,要查询两个表的数据要怎么查?
- 全局查询法,把每个表中的前xx条取出来,然后进行分页
- Sharding-Jdbc分页修正 就是上面的方案
- 缺点:深分页就不行了
- 不允许跳页,只能顺序往下查
- 二次查询法
分库分表的优缺点是什么?
优点:提升性能,增强存储能力
缺点:复杂查询不能,分布式事物
分库分表业界有哪些替代方案?(提示:分布式文件系统,因为分库分表会出现降低QPS,比如range查询失效)
为什么做了分库分表后分页比较困难了?
数据不在一个表中,而且顺序不一样
如果10亿数据要分表,要怎么分?业务怎么切?
分库+分表
分库分表怎么保证数据一致性?
本身保证,xa 或者base
选的什么分片键?什么分片算法?
用用户id mod切分
分库分表后的分布式ID怎么做?
给我雪花
(2025年目前为止的牛客面经关于分库分表的问题收集)
总结:
分布式事务一致性问题
跨节点关联查询JOIN问题(解决方案:1.全局表 2.冗余字段 3.建立1:1的ER实体关系分片)
非分片键的查询问题(1.创建映射表 2. 前缀分片法 3.使用ES搜索引擎(最后才说要抬高立意)
全局分布式ID问题(1.UUID2.雪花算法3.mysql/Redis4.美团Leaf(1.Leaf-segment 2.Leaf-snowflake)
跨库跨节点分页查询问题(不会)
参考面试回答:(吟唱)
面试官:分库分表后、如何解决跨节点JOIN查询问题
<参考回答:>
分库分表后、跨节点 JOIN 查询会带来性能问题。 为了解决这个问题主要有以下几种方案:
全局表: 如果是一些数据量小、变动不频繁的基础数据(比如权限表、配置表、商品分类表)可以将它们复制到每个数据库节点。 这样查询时可以直接在本地 JOIN、避免跨库。 但需要保证全局表的数据同步。
冗余字段: 如果经常需要 JOIN 某些字段、可以将这些字段冗余存储到需要查询的表中。 比如在订单表中冗余存储用户的姓名和地址。 这样查询订单信息时、就不用 JOIN 用户表了。 但需要保证冗余字段的数据一致性。
ER 分片: 如果表之间存在很强的关联关系、比如订单表和订单详情表、可以按照相同的规则进行分片、保证它们在同一个数据库节点上。 这样就可以避免跨库 JOIN。
(ER: 例如将订单表 和订单详情表按照 订单ID进行分片)
使用一致性哈希算法、将 订单ID映射到不同的数据库节点上。
关键: 保证具有相同 订单ID 的订单表记录和订单详情表记录、始终被分配到同一个数据库节点上。)
面试官:非分片键的字段如何查询问题
<参考回答:>
问题背景:我们选择分片键的时候都是选用查询场景最多的字段来做分片键、但是可能需要查询非分片键下的所有所有数据。例如电商用(订单ID) 做分片但是我们可能会查询订单类型、这些数据可能被分到了不同的库、我们需要聚合所有库的查询、然后返回给前端。导致效率低下
回答参考方案:
1.关系映射表:映射关系表就是存储待查询字段和分片键映射关系的一张表、当要使用非分片键查询的时候、先到映射关系表中查询字段所对应的所有分片键、再根据分片键查询所有信息。
(例如创建一个额外的映射表Map、包含 订单ID 和 订单类型 的对应关系。当插入新订单时、同时更新这个映射表。查询时先查映射表获取所有的 订单ID、再根据 订单ID列表查询分片表。总结一下就是用映射去查询我们就可以得到了 缺点是要维护新的Map 适用于对实时性要求不高的情况)
2. 前缀分片法:利用(订单ID)的某些特征来决定数据存储在哪个分片上,并将这个嵌入到主键中。 这样既可以通过主键进行分片、又可以通过UID进行分片。
(例如在生成 订单时,嵌入 用户ID 的某些特征 例如 用户ID的最后一位。然后使用包含这个 订单ID进行分片。这样既可以通过 订单分片,也可以通过 用户ID的特征进行路由。优点不需要额外的存储空间 缺点是可能会产生如果 用户ID分布不均匀、可能会导致数据倾斜)
3.ES: 将所有订单数据同步到ES中、利用 ES 的全文检索和聚合分析能力、进行多条件查询
面试官:分库分表后的分布式ID怎么做?
<参考回答:>
问题背景:分库分表后需要一个唯一ID来标识一条数据或消息。
回答参考方案:说一下各大方案及优缺点就行。
- UUID(优点本地生成、缺点是16字节128位存储成本高以及会产生页分裂问题
2.雪花算法(优点生成性能高、可以根据业务特征分配Bit位、缺点是依赖强时间回钟)
3.MySQL自增主键和Redis的Incr命令(不做探讨)
- 分布式ID生成服务、如美团的leaf算法(Leaf-segment和Leaf-snowflake)
大家这里可以去看美团技术文章 这里引导一下思路就好
面试官:如果要你选择一个分布式ID生成方案你会选什么
<参考回答:>
1.如果 对 ID 的有序性有要求、且需要高性能的 ID 生成服务、我会优先选择雪花或者 Leaf-snowflake 。 雪花的优点是生成速度快、ID 趋势递增、有利于数据库索引的性能优化。Leaf-snowflake 在雪花的基础上、对时钟回拨问题进行了优化
2.如果 对 ID 的有序性没有要求、且可以容忍一定的存储空间浪费、我会选择 UUID。 优点是本地生成、不需要依赖外部服务、生成速度快。
3.如果 业务规模较大、对 ID 的全局唯一性、高性能和可扩展性有较高要求、我会选择构建一个专门的分布式 ID 生成服、例如使用 Leaf-segment 算法。 的优点是统一管理、方便维护和扩展、可以根据业务需求定制 ID 生成规则。